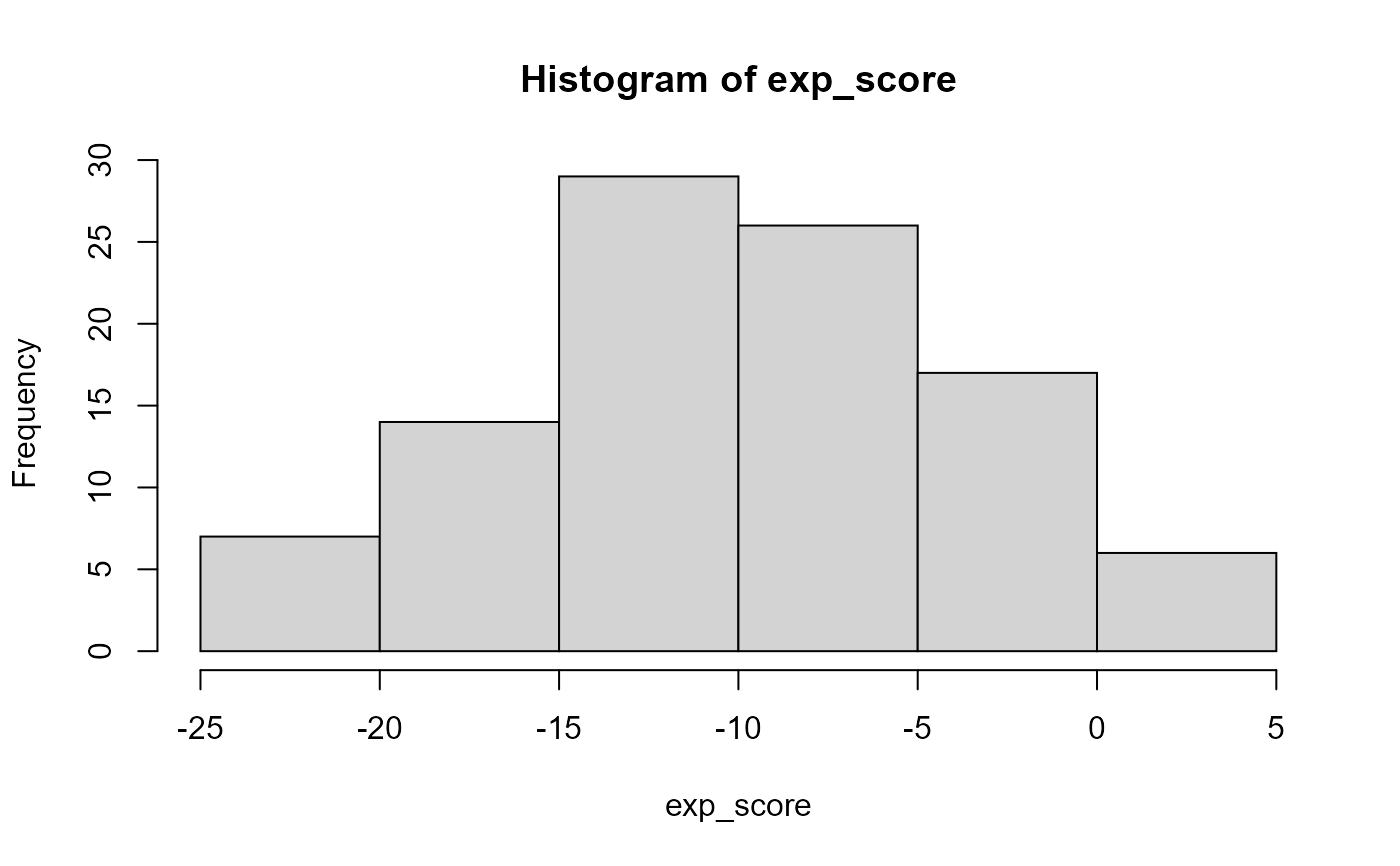
Returns a list of expected opinion scores with length equal
to the number of simulation (nsim) specified.
Employs non-parametric randomization testing approach in
order to generate the expectation distribution of the observed
opinion scores (see details in Adepeju and Jimoh 2021).
(1) Adepeju, M. and Jimoh, F. (2021). An Analytical
Framework for Measuring Inequality in the Public Opinions on
Policing – Assessing the impacts of COVID-19 Pandemic using
Twitter Data. https://doi.org/10.31235/osf.io/c32qh
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`
#> Adding missing grouping variables: `keywords`